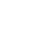2021国际AIOps挑战赛亚军铃动时序智能团队方案介绍
发布时间:2021-12-01 16:56:06
团队介绍
铃动时序智能团队由阿里巴巴达摩院决策智能实验室数据决策团队和阿里云数据库NoSQL产品部领衔(领队:达摩院高级算法专家何凯),联合浙江大学陈岭教授团队、大连理工大学刘胜蓝教授团队组成。达摩院决策智能实验室聚焦于时序数据分析、XAI、因果推断、MindOpt大规模优化求解器等技术方向,探索数据决策过程中核心问题的解决,打造统一的数据决策产品。团队的技术研发成果已在多个顶级会议(如KDD、SIGMOD、AAAI、IJCAI、ICASSP)等发表。团队研发的MinDAnalytics数据决策。

02 / 赛题解读
本次比赛采用的数据模态较多,包括时序黄金指标、性能指标、调用链以及首次加入的日志数据。其中性能指标的体系庞大(涉及系统OS、内存、磁盘、中间件、数据库等),绝大多数指标中的噪音较强,周期会动态改变,对鲁棒的检测算法提出了很高的要求。同时,由于故障实体(cmbd)在复杂的拓扑结构中存在依赖关系,导致同一时刻可能检测出多组可疑的根因对象,需要算法能够去伪存真定位真正的故障原因。需要特别指出的是,赛题包含两家真实的银行应用系统,其结构(A系统水平扩展较B系统更大)和数据形态与波动差异较大,这对设计统一且通用的算法框架提出了很大的挑战。
根据赛题的要求,返回的故障根因只能包含性能指标和服务日志,因此我们将这两种数据作为直接定位的“根因指标”,而将黄金指标和调用链数据的分析作为“线索指标”。常见的故障定位通常为“自上而下”顺着线索指标下探到根因指标。由于此次赛题中根因指标的波动不一定会引起上游黄金指标的异常(如水平扩展较多的A系统),我们这里的首个创新为采用“自下而上”的方式去伪存真,直接分析根因指标并辅以线索指标进行验证,见图1.

图1.赛题分析
03 / 方案介绍
图2给出了铃动时序智能团队的整体计算架构。从Kafka实时接收的性能指标和日志数据首先会流入我们设计的TSDB数据库中进行ETL和抹平乱序等预处理。接下来我们的鲁棒异常检测算法会对离线训练中筛选出的重点性能指标和日志信息进行实时离群点分析,并根据与其关联的故障类型进行初步判断和汇总。第三步我们利用习得的故障类型之间的优先级关系和系统拓扑结构,定位真正的根因。具体每部分的算法设计将在下面重点展开。
需要指出的是,为了对特定的单日志类根因进行快速识别,我们设计了基于关键词提取的日志快速分析模块进行“抢答”操作,降低故障定位延时。
通用性方面,我们使用上述统一的架构来处理不同的应用系统,并以系统配置文档的形式进行参数设置。为了进一步提高易用和扩展性,我们设计了离线自动调参模块来进行自动最优参数搜索,并支持添加专家先验知识到配置文件里。
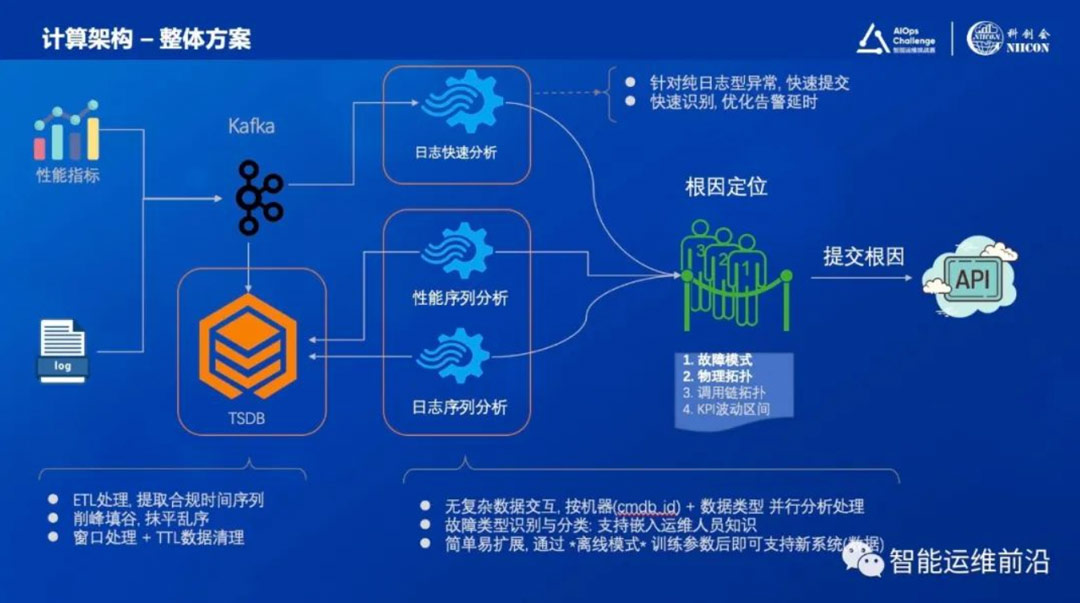
图2.计算架构-整体方案
下面具体介绍算法的实现与创新:
3.1 鲁棒性时序异常检测算法及自动参数调节

图3. 鲁棒性时序异常检测
这里的一个挑战为故障涉及的类型和指标非常多,需要高效的方法为Robust T-test算法选择合适的参数(包括左右窗口的长短、统计显著水平)。为此我们开发了一套基于Grid Search的自动参数调节模块,在离线训练时根据已知故障标签数据为每种故障类型的指标进行最优参数选择。
3.2 指标自动相关性分析与故障分类
如第2小节中所述,赛题涉及的性能指标达数以千计,每次都进行全盘扫描不仅耗时严重,也会为离线参数调优带来挑战。为了缩小在线根因定位的指标搜索范围,我们提出了一套自动的指标相关性分析和故障分类算法。
具体来讲,我们结合FastDTW与皮尔逊相关系数先在离线环境里从故障标签数据中提炼出高度相关的指标集合,如图4中当gjjcore8出现cpu类指标异常时,多组相关指标呈现相似或相反等高度相关的异常变化。通过相关性分析,我们可以找出这些高度相关的指标,对其中的代表进行异常检测,来减少根因定位的扫描范围从而降低计算开销。选择FastDTW算法是我们考虑到跟故障相关的指标可能在时间轴上存在时延,通过计算每对性能指标在故障时刻左右的DTW距离来定位与目标时间序列相关但是存在时延的指标集合。
我们将这些相关的指标与故障类型按照标签数据里的故障时刻和数据波形进行对照,总结出了一份故障类型和对应指标的信息。对于每种故障类型,我们认为当与该故障相关的指标集合中有超过一定数量的指标同时报警时,该故障类型才会进入我们的根因候选集合。同样的,每种类型相关的阈值信息也是通过离线学习。
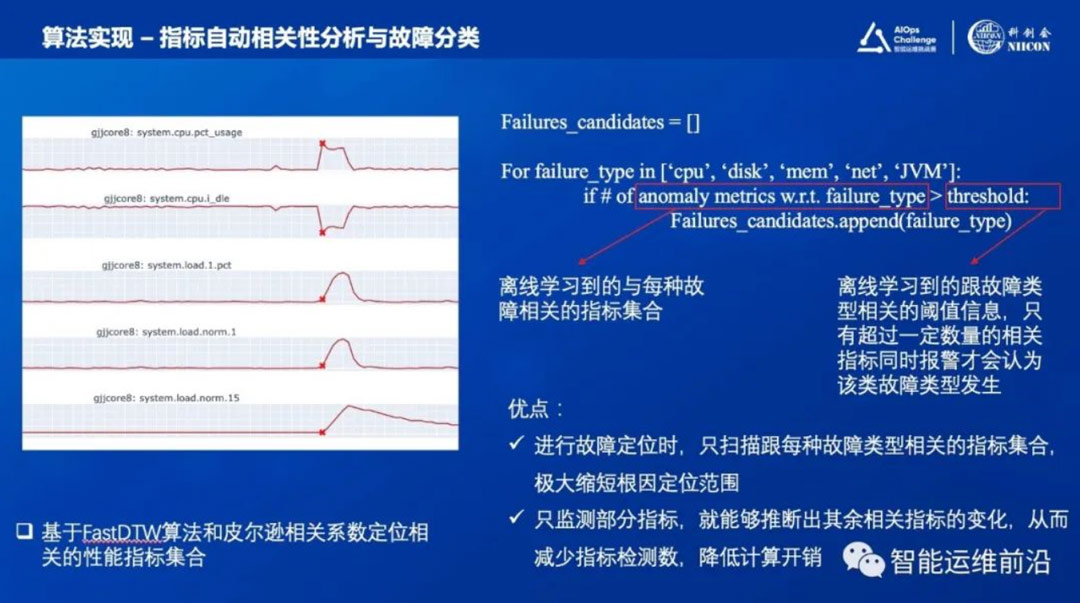
图4. 指标自动相关性分析与故障分类
3.3 根因定位
我们发现,在标签数据提供的故障时刻左右,常会出现多种故障类型(即3.2中找到的根因候选集合成员不唯一),这其中只有真正的根因故障才是我们需要识别和提交的。如图5右侧,A系统出现的磁盘故障可以引起同时段内的CPU负载和使用率也明显异常。因此我们通过离线学习和利用专家知识,提出了一套故障的优先级标准,当多组故障同时出现时,我们会锁定高优先级的故障及其指标进行提交,例如磁盘>CPU, 内存>CPU等。
同时,我们也观察到在系统的拓扑结构上,可能同时存在多个故障实体(cmbd),有上下游关系。这种时候要根据系统的拓扑结构定位到真正的上游实体,如图5左侧B系统的Mysql01网络隔离导致上游Tomcat异动,此时应该提交Mysql01为真正的根因。类似地,我们将拓扑的结构信息也作为先验知识,并设定优先级以在多组cmbd实体异常时进行真正的根因定位。

图5. 根因定位
3.4 报警抑制
在本次比赛中,重复提交答案会占用提交次数,并且带来时延(后提交的答案会覆盖前者,定位时间也会随之推后),降低得分,所以我们设置了如下的报警抑制函数:
故障异常分=预估根因数/提交答案延时
其意味着只有当新发现的根因数的增益大于延时的损耗时,才会再次提交一次答案。图6给出在使用抑制后的实际效果。
图6.报警抑制
3.5 算法通用性与扩展
整体的通用性设计和离线自动化学习已在前面小节中介绍,这里不再赘述,参见图7.
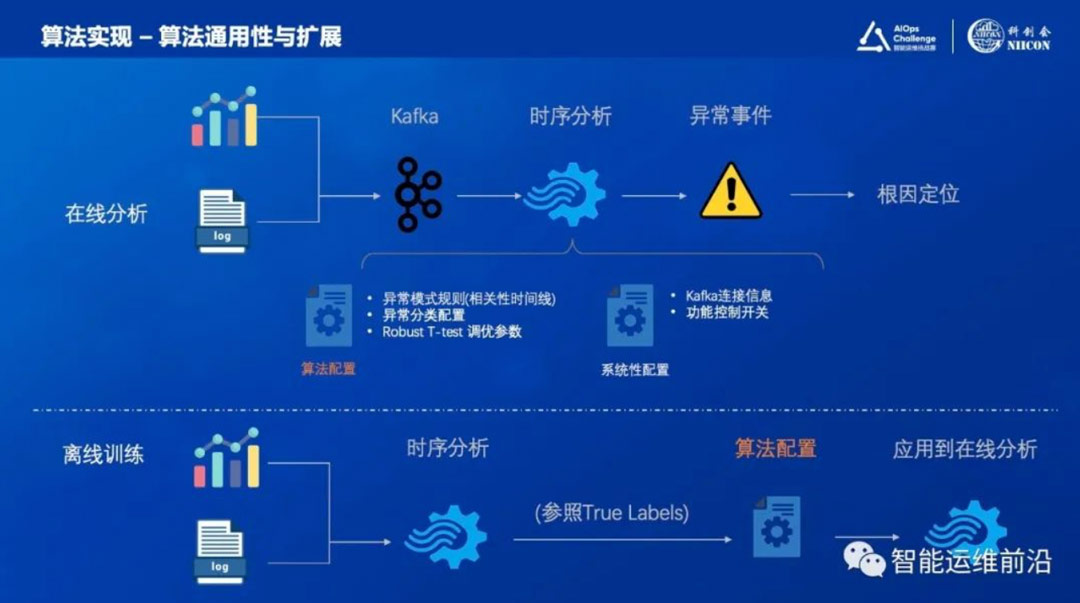
图7.算法通用性及扩展
04 / 总结与展望
本次比赛中,我们提出使用鲁棒性时序异常检测算法,以有效处理高噪音数据。配合设计了自动挖掘指标间的相关性和自动参数调节算法,来提炼与故障最相关的指标集合并提升通用性。通过学习故障的优先级、利用系统拓扑结构、以及设计巧妙的Ranking函数,我们的方案可以有效的定位真正的根因并减少误报和重复报警。
我们提出的算法易用性强,可以进行效果的快速复制和大规模部署,目前在我们的产品MinDAnalytics中已经通过使用RobustPeriod【1】周期判断和RobustSTL【2,3】时序分解在阿里内部成功落地多项场景。
对于未来潜在的提升方向,我们认为对多指标系统进行整体建模和状态分析值得探索,如结合所有的数据源信息对系统当前的状态进行建模,再进行异常检测。
参考文献
Qingsong Wen, Kai He, Liang Sun, Yingying Zhang, Min Ke, and Huan Xu, RobustPeriod: Time-Frequency Mining for Robust Multiple Periodicities Detection," in Proc. ACM SIGMOD International Conference on Management of Data (SIGMOD 2021)
Qingsong Wen, Jingkun Gao, Xiaomin Song, Liang Sun, Huan Xu, Shenghuo Zhu. RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series. Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI 2019)
Qingsong Wen, Zhe Zhang, Yan Li and Liang Sun, Fast RobustSTL: Efficient and Robust Seasonal-Trend Decomposition for Time Series with Complex Patterns, in Proc. of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD 2020), San Diego, CA, Aug. 2020.
详细答辩ppt可以访问链接获得。
https://workshop.aiops.org/