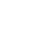必示科技刘大鹏:知识与算法结合的智能排障方案
发布时间:2021-05-27 19:41:00
大家好!
今天我从一个很具体的点——排障场景,跟大家分享一些实践经验。我分享的题目是《知识与算法结合的智能排障方案》。
提起人工智能,大家脑海中第一印象可能是下图左侧的这些酷炫的词汇。但从真正的实践来看,人工智能是一个广泛的定义,指的是模拟人的行为的一种计算机技术,不仅仅是算法本身,而是包括知识、数据、算法和算力四个要素。我们对人工智能的第一印象,其实只是人工智能四要素的其中一环。

为什么我们会有这样的固有印象?这是由于我们平时在做智能运维相关工作和方案设计时,已经有专家根据运维知识提前定义了若干明确的场景,剩余工作看起来就是解决这些具体场景,做好算法优化和设计工作。
这里做一个比喻,就像不同的桶装不同的水,先由既有运维经验又有一定算法能力的专家定义好“桶”,“桶”即专家根据知识定义的问题;然后在上面做算法研究,往里面倒“水”,“水”即用算法解决具体问题,把“算法”做得越来越好,把“桶”倒得越来越满。
我们总容易看到算法,但实际上背后有很多领域知识。比如本届国际AIOps挑战赛题目,及其背后很多问题的解决,都包含了很多运维经验和知识。
必示科技团队在智能运维实践过程中,经历了几个阶段。第一阶段,我们联合合作企业的专家们一起定义了一些常见场景,定义了一些“桶”,比如利用业务指标数据做异常检测、利用交易数据做定位、利用机器数据做定位、利用中间件层面指标做定位等。我们在这样明确的场景中去做好算法达到预期效果。但依然是先有人根据经验框定了具体范围,正是因为框定了这些范围,才有可能做好算法设计,因为算法解决的是明确、具体的问题。
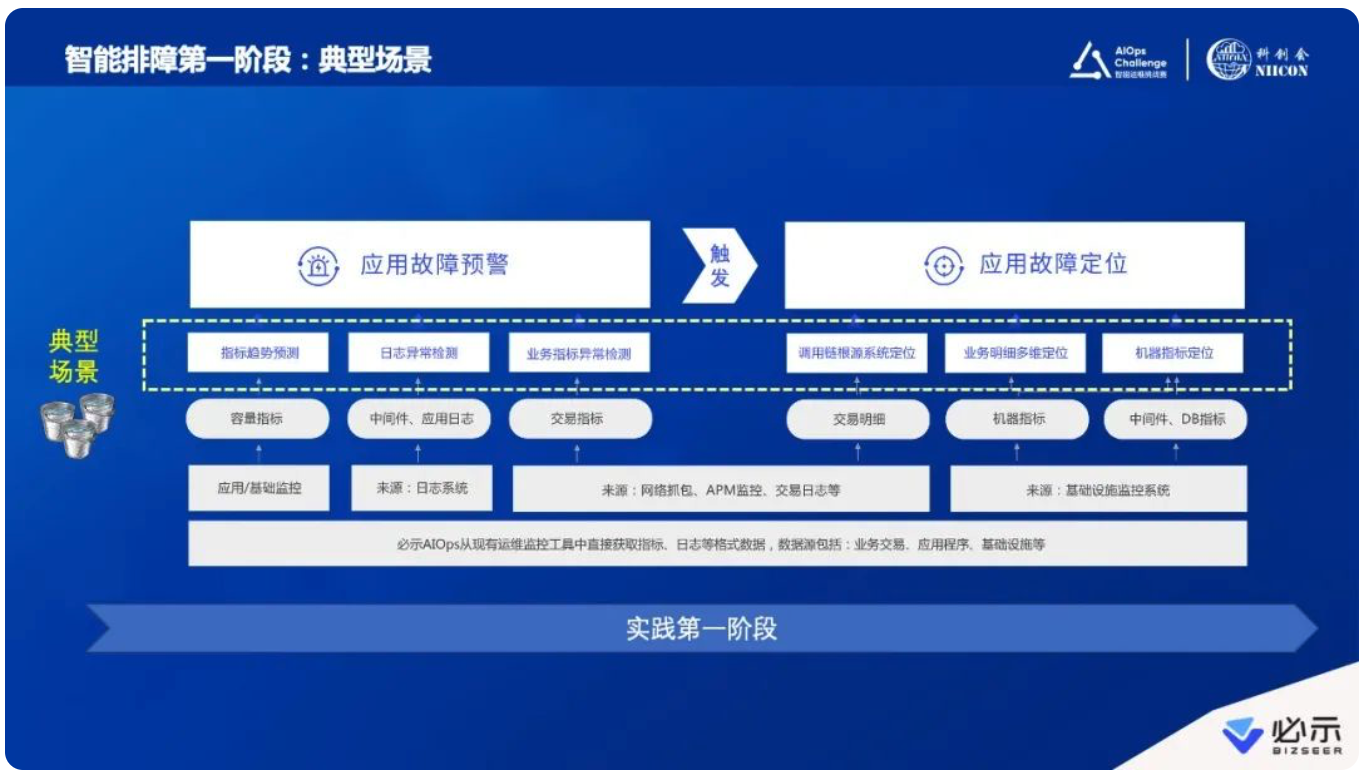
比如业务指标异常检测,指标的形态多种多样,怎么去设计算法?银行可能有几百套系统,不同系统的业务模式不一样,指标形态也不一样。针对不同形态的业务指标,比如交易量、响应时间、成功率、响应率等,算法怎么能够做到鲁棒性更强?在检测出异常之后,怎么通过跨系统调用、多维度的交易明细数据、底层机器层面的数据去做定位?这些都是很具体的问题,才有算法去发挥实力的空间。
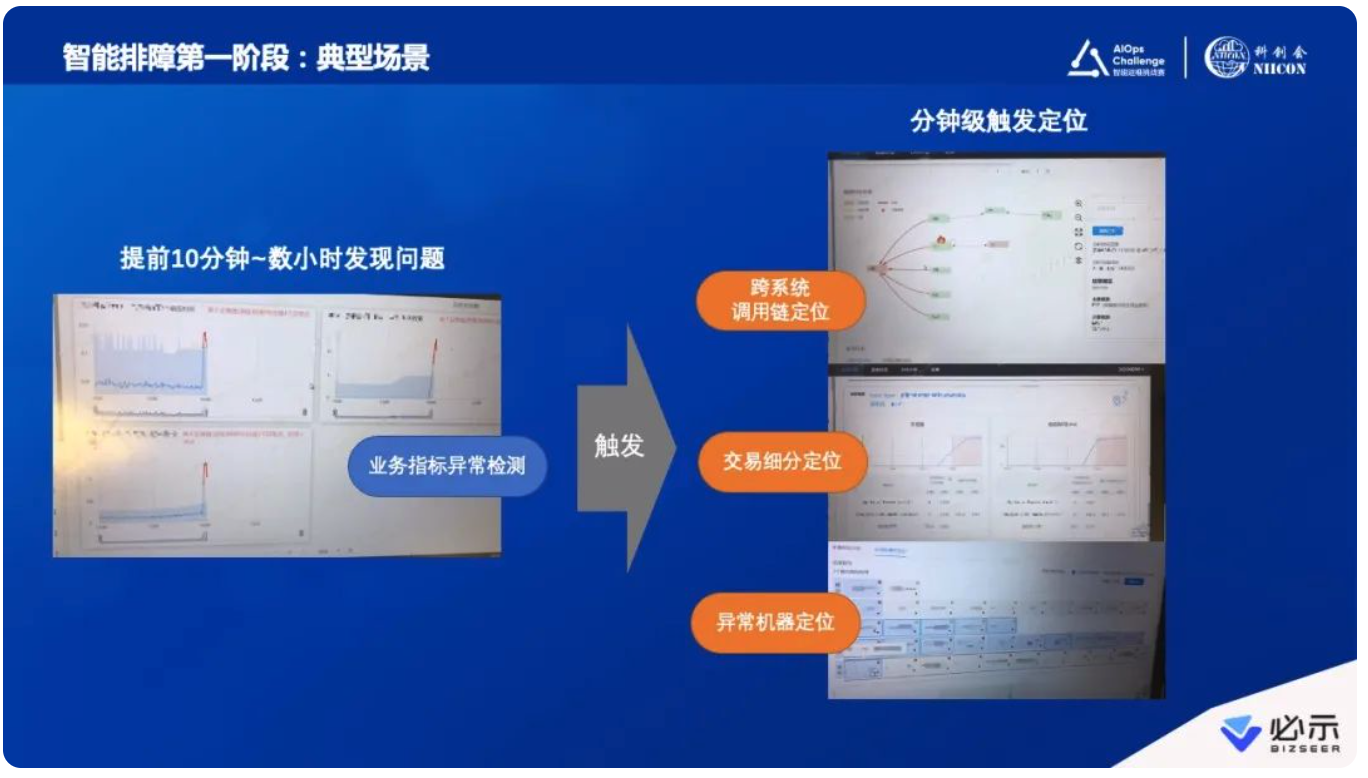
这个模式是过去几年智能运维实践最主流的一种方式,确实带来了很多业务价值。比如发现故障时间提前30%,比如故障告警准确率可以达到97%,比如故障的定位时间减少82%。下图右侧也列了几个具体案例,汇总了一些实践中的数据。这是我们利用第一阶段专家定义好的“桶”、再由算法专业人士做好算法的模式,所带来的一系列成效。
伴随这样的实践往前走,我们发现开始遇到新的挑战,如同看到冰山一角逐渐延展开一样,要解决的场景(桶)特别多。大家可以看下我列的标题,“行业×技术架构×运维对象×数据源×故障类型”,乘积之后问题维度变得特别多、特别繁杂。
不同的行业,从金融、运营商、能源、电力到制造业等;不同技术的迭代,从最早的集中式架构到开放式架构,再到容器化、微服务;再到不同组件的更新换代,包括国产化的组件等,都带来了运维对象的改变。
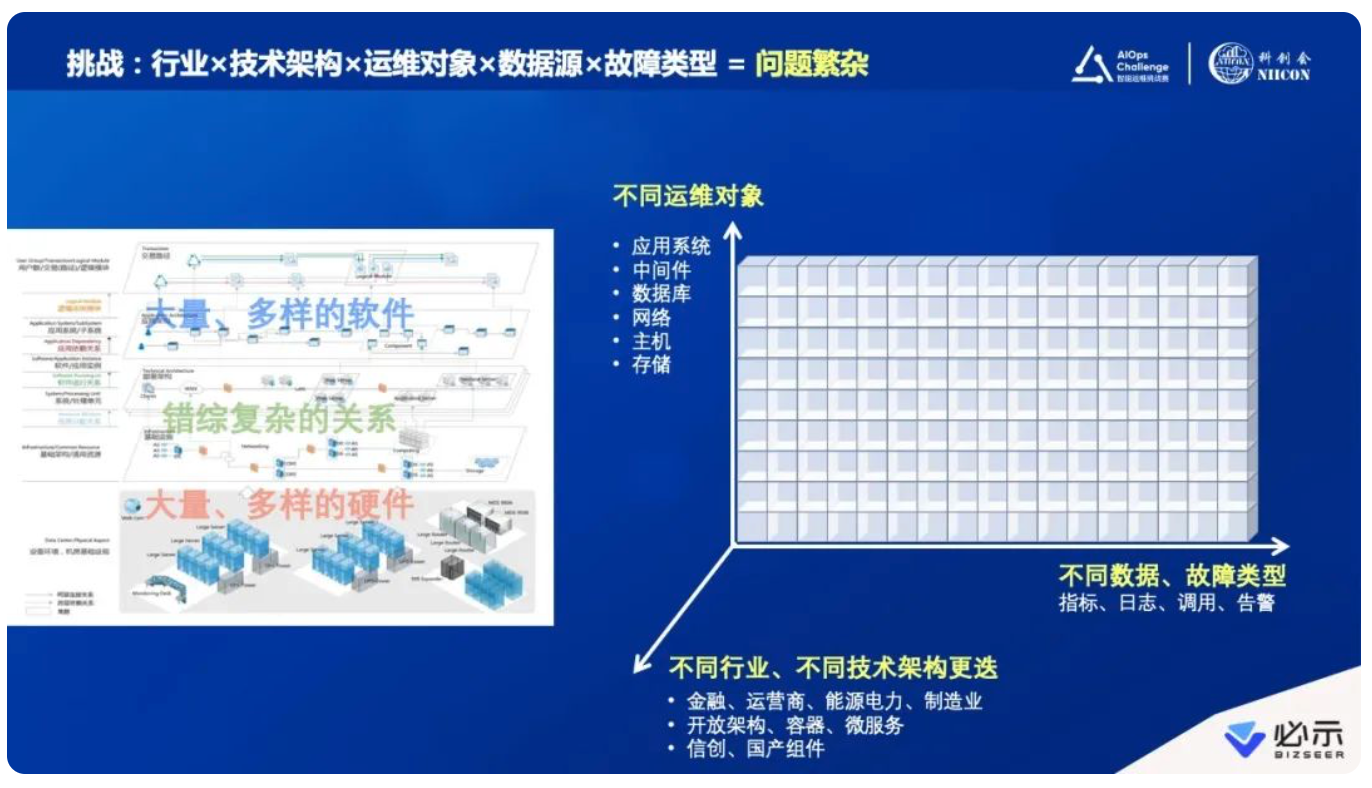
整个运维架构中,有很多不同的运维对象,每一个运维对象的问题、数据、每一种故障类型都会不同。可以看到,这个空间很大,每一个小的方块都相当于一个明确要去解决的问题。如此一来,我们需要一个更加系统化的方法,把智能运维按照能够不断扩展、成体系化的方向去建设,不再是单点、零散地逐一突破,这就进入到第二阶段。
为了解决问题,最重要是把知识纳入进来。比如,在2021国际AIOps挑战赛比赛过程中,选手需要用一些指标和日志去做故障定位。比赛中没有给出SQL层面的详细数据,如果给你的话你会怎么做?你再去做一个算法对数据库层面做检测,检测后的结果如何跟之前的东西链接起来?将来再把存储或者底层网络的数据给你,怎么把做的这么多算法有机地组合起来,然后在上面做定位?这里,知识就变得不可或缺,需要把它纳入到整个系统建设,也许是一个步骤,也许是一个核心构成。
通过下图,我们可以看到知识包括很多内容,比如定义不同数据源需要检测什么样的异常信号,比如不同数据源检测出来的异常信号之间的因果关系和时空关系。时空关系,典型的如组件之间的部署关系、调用关系。因果关系更多的是我们通过计算机的常识与经验,比如当线程池变高之后经常要排查什么问题。
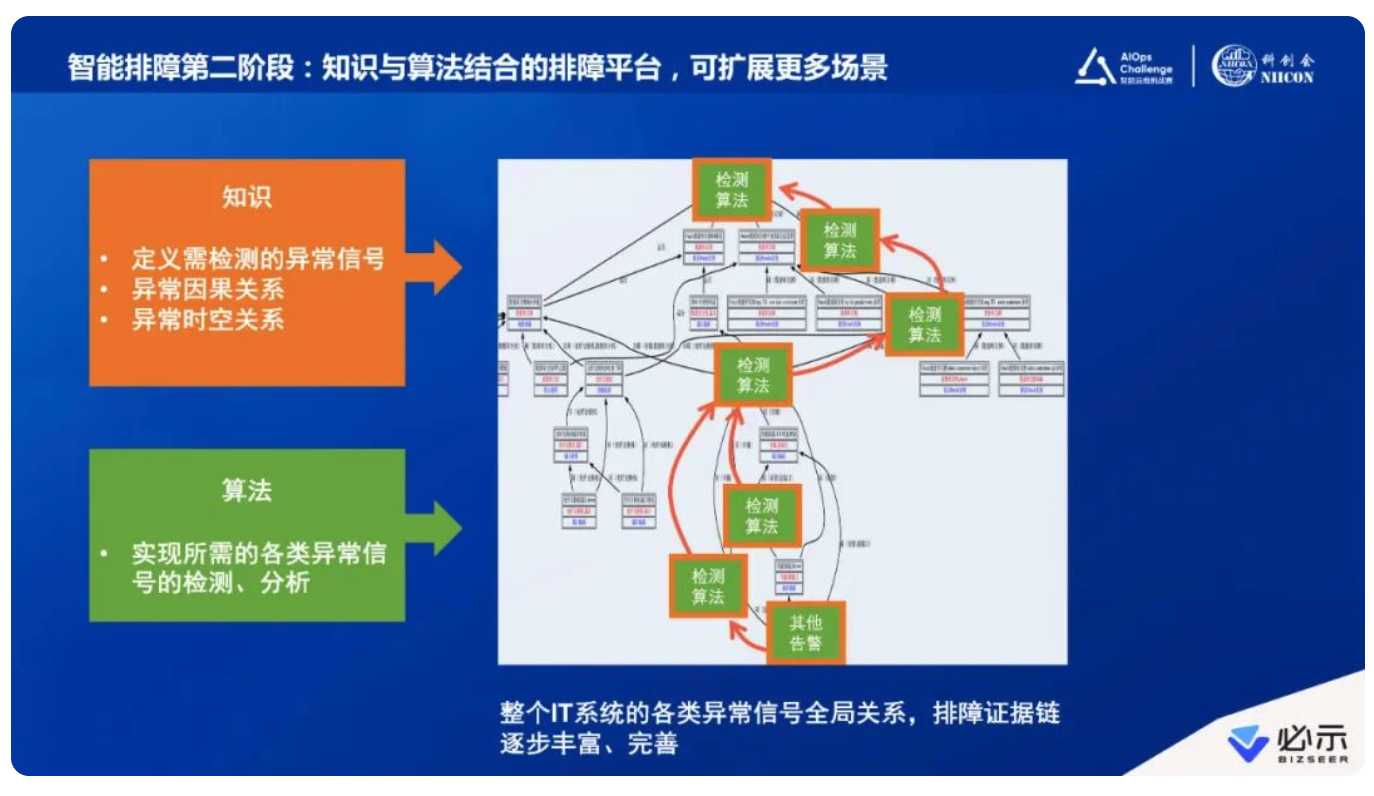
当把整个智能运维的架构定义出来之后,上图中橙色小方块,加上这些“边”就是它们的时空关系和因果关系。接下来就是算法的发力点,每一个层次的小方块都是一个明确的问题,都有明确的数据输入和需要得到的明确输出。这里要对不同的算法做逐一突破,将来可以不断地去延展。
接下来,整个架构会成为一个数据中心级的智能排障平台,至少从我们的实践经验来看,最佳实践就是按照经验知识与算法结合的方式去建设平台,然后再逐渐扩展。第一期的时候,数据可能比较有限,数据质量好的可能也只有一部分。这没关系,按照这个思路来,最开始点亮的模块可能会少一点,排查的范围会少一点,之后会逐步增加。
比如说下图(右侧色块对应的位置),上面的域可能是应用系统管理员经常会排查和检测的问题,我们知道应用其实依赖各种各样的服务运行在各种中间件上,比如Weblogic、WAS、Tomcat等。这些中间件的领域知识又有排查的异常,可能有指标,可能有日志,也可能有别的内容。最下面会连接数据库,包括Oracle、MySQL等数据库,包括DBA经常排查的内容,有些可能是简单的规则阈值,有些就需要动态适配的算法。按此架构,我们可以不断地扩展排障领域。
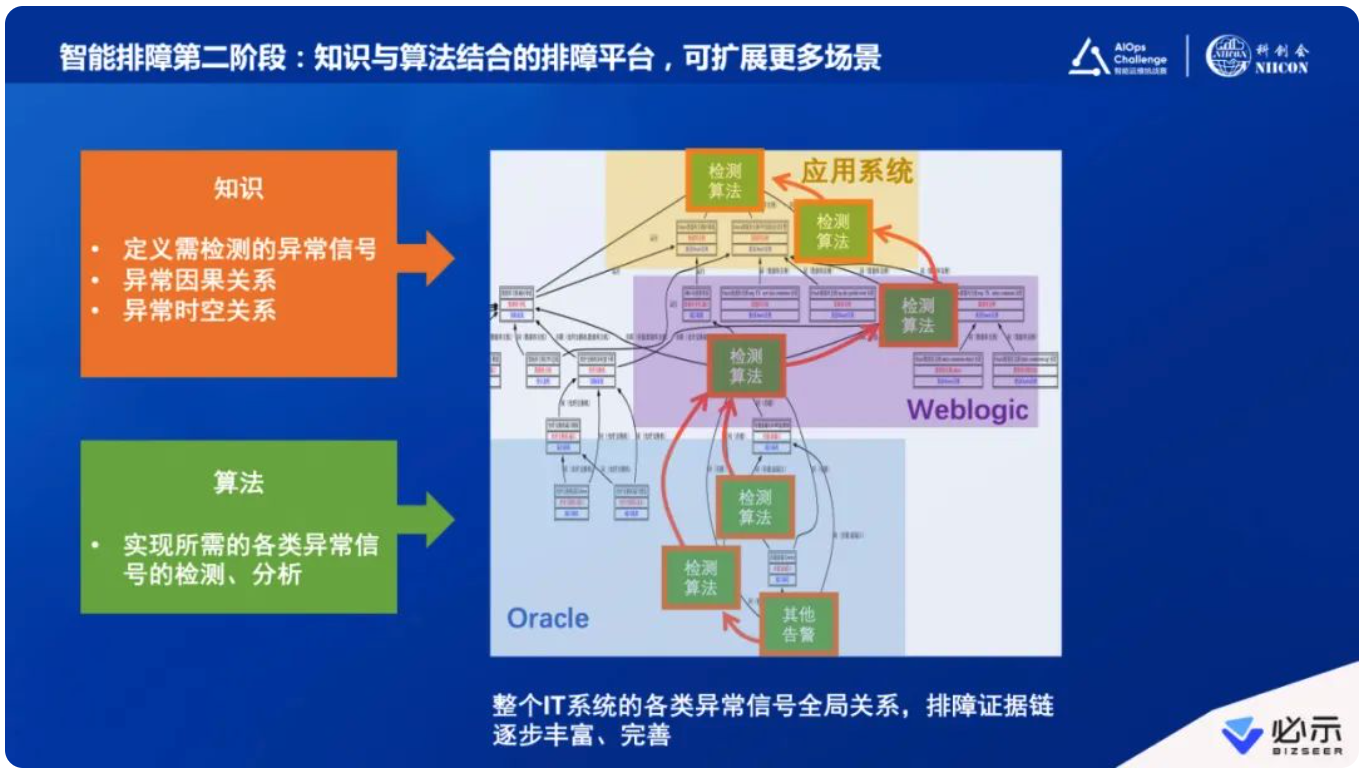
所以,第一期可能只做这一块,甚至只做这一块里面的一小部分。随着数据质量的完善,算法逐步开发,这个平台会逐渐扩展,整个数据中心运维智能化的覆盖面也会越来越大。这是我这次演讲跟大家分享的最关键的地方,一定不能把橙色部分(知识)抛弃掉,只关注绿色部分(算法)。
关于经验,或许很多专家会有疑问:经验能不能共享和复制?这是一个好问题,经验确实可以共享复制,这恰恰是运维这个AI可落地的黄金行业可以做的事情。因为我们有非常多的标准化组件,排障和经验是可以被复制的。不同的企业之间,Oracle、交换机,或者底层的操作系统,虽然各家企业可能有些自己常见的问题,但是在排障方面的交集是很大的,而且全集是可共享的。举一个直观的例子,比如某银行的DBA找工作,其他银行或其他企业会不会考虑招?答案是肯定的,因为他的经验可以在其他银行和领域内复用。
知识本身涉及到积累,与运维对象的建模如出一辙,对不同的应用对象进行建模,就是它应该有怎样的数据、检测怎样的问题、如何检测。我们实践中也积累了各种常见组件的排障知识、不同组件要做怎样的算法,整个场景是可以不断去扩展和积累的。
最后总结一下。第一点想说,必示科技团队从2017年开始做智能运维实践落地,经过一段时间的探索逐渐进入到刚才提到的第一阶段,我们找到了运维中一些很典型的、数据普遍具备的场景,围绕这些场景做了很多算法,然后深耕、做穿、打透。我们逐渐发现运维细分场景越来越多,开始进入到第二阶段后,我们愈发认识到算法跟知识同等重要,运维专家对运维场景的梳理和拆解非常关键,在构建整个智能运维架构后才有算法发挥的空间。
第二点想说的是,运维是一个非常关注实际效果的行业,所以智能运维也要从实际场景出发,不是拿锤子去找钉子,不是说手头有一堆算法看看在运维场景能解决什么问题,而是要构建出运维实际场景到底需要什么,然后为它去研制算法,即便这个算法之前不存在。这个是非常有效的方法,分阶段进行建设,逐步扩展、逐步积累。最重要的是不同企业之间的排障经验,通过平台被复制,我们就去构建这样的生态。比如将来AIOps挑战赛出的很多题目,大家在上面做的事情,就有可能变成企业真正运维里的一个环节。

以上就是我分享的内容,因为时间有限,很多细节没有展开,希望能抛砖引玉,对大家在智能运维这条路有所帮助。谢谢大家!